Create articles from any YouTube video or use our API to get YouTube transcriptions
Start for freeUnderstanding OpenAI's Whisper Model
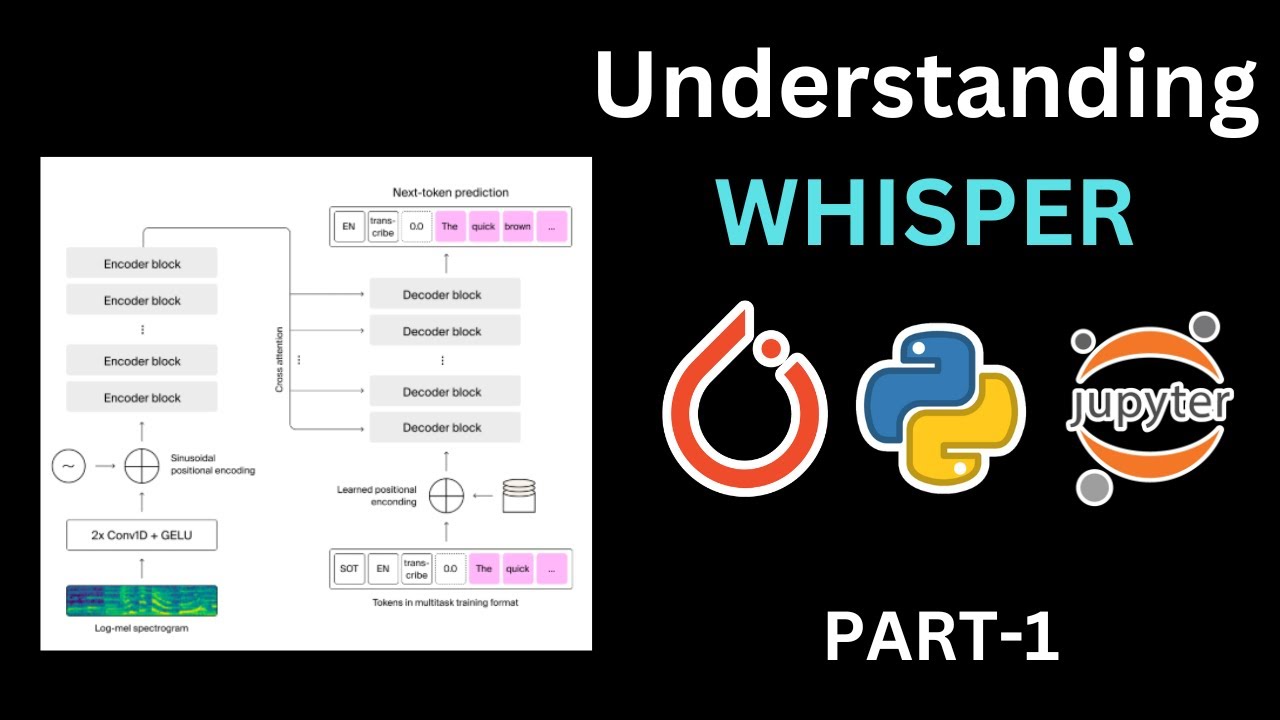
OpenAI's Whisper model has revolutionized the field of speech recognition. This powerful tool utilizes an encoder-decoder structure to process audio data and generate accurate transcriptions. Unlike its cousin ChatGPT, which relies solely on a decoder structure, Whisper's encoder component allows it to handle the complexities of audio input effectively.
Key Components of Whisper
The Whisper model consists of three main components:
- Feature Extractor: Converts raw audio data into log-mel spectrograms
- Tokenizer: Transforms text into numerical tokens
- Model: Processes spectrograms and generates transcription tokens
Feature Extractor
The feature extractor is responsible for converting raw audio data into log-mel spectrograms. These spectrograms serve as the input for the encoder part of the Whisper model. It's crucial to note that Whisper is trained on audio data with a sampling rate of 16,000 Hz. If your audio has a different sampling rate, you'll need to downsample it to match this requirement.
Tokenizer
The Whisper tokenizer takes a sentence in any supported language and converts it into numbers that the machine can understand. It adds special tokens at the beginning and end of the sequence, such as "startup transcript," "English," "transcribe," and "end of text."
Model
The core of Whisper is its model, which processes the log-mel spectrograms and generates token IDs as output. These token IDs can then be converted back into readable text using the tokenizer.
The Whisper Process
- Audio input is converted to a log-mel spectrogram
- The spectrogram is passed through the Whisper model
- The model outputs token IDs
- Token IDs are converted back to readable text
It's important to note that the output text size is fixed at 448 tokens for 30 seconds of audio. If the generated text is shorter, it's padded with -100 values.
Practical Implementation of Whisper
Let's dive into a practical implementation of the Whisper model using Python and popular libraries.
Setting Up the Environment
First, we need to install the required libraries. These include transformers, datasets, evaluate, jiwer, and accelerate. These libraries are crucial for working with the Whisper model and processing audio data.
!pip install transformers datasets evaluate jiwer accelerate
Loading and Preparing the Dataset
For this example, we'll use an air traffic controller dataset. This dataset is particularly challenging because it contains unique terminology that the default Whisper model may not recognize.
from datasets import load_dataset
dataset = load_dataset("audio", data_files={"train": "atc_train_1.zip", "validation": "atc_val_1.zip"})
Let's examine the first sample in our dataset:
first_sample = dataset['train'][0]
print(first_sample)
The output will show the audio array and the corresponding transcription.
Processing Audio Data
To work with the audio data, we'll use numpy and IPython's display.Audio:
import numpy as np
from IPython.display import Audio
audio_original = first_sample['audio']['array']
original_sample_rate = first_sample['audio']['sampling_rate']
print(f"Total samples: {len(audio_original)}")
print(f"Sample rate: {original_sample_rate}")
Audio(audio_original, rate=original_sample_rate)
If the sampling rate isn't 16,000 Hz, we'd need to resample the audio:
from scipy import signal
if original_sample_rate != 16000:
audio_resampled = signal.resample(audio_original, int(len(audio_original) * 16000 / original_sample_rate))
Audio(audio_resampled, rate=16000)
Tokenization
Next, we'll tokenize the transcription text:
from transformers import WhisperTokenizer
tokenizer = WhisperTokenizer.from_pretrained("openai/whisper-small")
text = first_sample['text']
tokenizer_output = tokenizer(text, return_tensors="pt", padding="max_length", max_length=448)
encoded_target = tokenizer_output['input_ids'].squeeze()
attention_mask = tokenizer_output['attention_mask'].squeeze()
We'll replace padding tokens with -100:
encoded_target[attention_mask != 1] = -100
Feature Extraction
Now, let's extract audio features using the Whisper feature extractor:
from transformers import WhisperFeatureExtractor
feature_extractor = WhisperFeatureExtractor.from_pretrained("openai/whisper-small")
input_features = feature_extractor(audio_original, sampling_rate=original_sample_rate, return_tensors="pt").input_features
Making Predictions with Whisper
Let's use the Whisper model to make predictions:
from transformers import WhisperForConditionalGeneration
import torch
model = WhisperForConditionalGeneration.from_pretrained("openai/whisper-small").to("cuda")
with torch.no_grad():
generated_ids = model.generate(input_features.to("cuda"), language="English", task="transcribe")
transcription = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(f"Predicted: {transcription}")
print(f"Actual: {text}")
Fine-tuning Whisper
To improve Whisper's performance on our specific dataset, we can fine-tune the model:
model.train()
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-5)
for i in range(30):
outputs = model(input_features.to("cuda"), labels=encoded_target.unsqueeze(0).to("cuda"))
loss = outputs.loss
loss.backward()
optimizer.step()
optimizer.zero_grad()
print(f"Iteration {i+1}, Loss: {loss.item()}")
After fine-tuning, we can compare the model's performance:
model.eval()
with torch.no_grad():
generated_ids = model.generate(input_features.to("cuda"), language="English", task="transcribe")
transcription = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(f"Predicted (after fine-tuning): {transcription}")
print(f"Actual: {text}")
Advanced Techniques for Whisper
Handling Longer Audio Files
Whisper is designed to handle audio segments up to 30 seconds long. For longer audio files, you'll need to implement a chunking strategy:
def chunk_audio(audio, chunk_length_ms=30000, sample_rate=16000):
chunk_length = int(chunk_length_ms * sample_rate / 1000)
chunks = [audio[i:i+chunk_length] for i in range(0, len(audio), chunk_length)]
return chunks
chunks = chunk_audio(audio_original, sample_rate=original_sample_rate)
Implementing Beam Search
Beam search can improve the quality of transcriptions by considering multiple possible sequences:
with torch.no_grad():
generated_ids = model.generate(
input_features.to("cuda"),
language="English",
task="transcribe",
num_beams=5,
early_stopping=True
)
Handling Multiple Languages
Whisper supports multiple languages. You can specify the language or let the model detect it:
with torch.no_grad():
generated_ids = model.generate(
input_features.to("cuda"),
task="transcribe"
)
Implementing Temperature Scaling
Temperature scaling can help control the randomness of the model's output:
with torch.no_grad():
generated_ids = model.generate(
input_features.to("cuda"),
language="English",
task="transcribe",
temperature=0.7
)
Optimizing Whisper for Production
Quantization
Quantization can reduce the model size and improve inference speed:
from transformers import WhisperForConditionalGeneration
model = WhisperForConditionalGeneration.from_pretrained("openai/whisper-small", device_map="auto", load_in_8bit=True)
Batch Processing
Processing audio in batches can significantly improve throughput:
batch_size = 8
batch_features = torch.stack([feature_extractor(chunk, sampling_rate=16000, return_tensors="pt").input_features for chunk in chunks[:batch_size]])
with torch.no_grad():
generated_ids = model.generate(batch_features.squeeze(1).to("cuda"), language="English", task="transcribe")
transcriptions = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
Caching
Implementing a caching mechanism can improve performance for repeated transcriptions:
import hashlib
import json
def get_cache_key(audio):
return hashlib.md5(audio.tobytes()).hexdigest()
def transcribe_with_cache(audio, cache):
key = get_cache_key(audio)
if key in cache:
return cache[key]
features = feature_extractor(audio, sampling_rate=16000, return_tensors="pt").input_features
with torch.no_grad():
generated_ids = model.generate(features.to("cuda"), language="English", task="transcribe")
transcription = tokenizer.decode(generated_ids[0], skip_special_tokens=True)
cache[key] = transcription
return transcription
cache = {}
transcription = transcribe_with_cache(audio_original, cache)
Evaluating Whisper's Performance
Word Error Rate (WER)
WER is a common metric for evaluating speech recognition systems:
from jiwer import wer
actual_text = "Oscar kilo Papa Mike Bravo decent flight level 100 level 100 Oscar kilo Papa mik Bravo"
predicted_text = transcription
error_rate = wer(actual_text, predicted_text)
print(f"Word Error Rate: {error_rate}")
Character Error Rate (CER)
CER provides a character-level evaluation:
from jiwer import cer
error_rate = cer(actual_text, predicted_text)
print(f"Character Error Rate: {error_rate}")
Conclusion
OpenAI's Whisper model represents a significant advancement in speech recognition technology. Its ability to handle various languages and accents, coupled with its open-source nature, makes it a valuable tool for developers and researchers alike.
In this article, we've explored the inner workings of Whisper, from its architecture to practical implementation. We've covered data preparation, tokenization, feature extraction, and prediction. We've also delved into fine-tuning the model for specific datasets, which is crucial for improving performance on specialized vocabularies like air traffic control communications.
The power of Whisper lies not just in its out-of-the-box performance, but in its flexibility and potential for customization. By fine-tuning the model on domain-specific data, we can create highly accurate speech recognition systems for a wide range of applications.
As we continue to push the boundaries of AI and machine learning, models like Whisper will play an increasingly important role in bridging the gap between human speech and machine understanding. Whether you're building a voice assistant, a transcription service, or a complex audio analysis system, Whisper provides a solid foundation for your speech recognition needs.
Remember, the key to getting the most out of Whisper is experimentation and iteration. Don't be afraid to adjust hyperparameters, try different fine-tuning strategies, or combine Whisper with other models and techniques. The field of speech recognition is rapidly evolving, and there's always room for innovation and improvement.
As you continue your journey with Whisper and speech recognition, keep exploring, keep learning, and keep pushing the boundaries of what's possible. The future of human-machine interaction is being written (or should we say, spoken) right now, and tools like Whisper are at the forefront of this exciting frontier.
Article created from: https://youtu.be/iGEJkvu0Qrg?feature=shared


