Create articles from any YouTube video or use our API to get YouTube transcriptions
Start for freeDiffusion models have emerged as powerful generative models, achieving state-of-the-art results in image generation tasks. In this article, we'll explore two key types of diffusion models - Denoising Diffusion Probabilistic Models (DDPMs) and Denoising Diffusion Implicit Models (DDIMs). We'll cover their core concepts, training procedures, and how they differ in terms of inference and inversion capabilities.
Denoising Diffusion Probabilistic Models (DDPMs)
DDPMs are a class of generative models that learn to gradually denoise data through an iterative process. The key idea is to model the reverse of a forward diffusion process that gradually adds noise to data samples.
Forward Process
The forward process in DDPMs is defined as a Markov chain that gradually adds Gaussian noise to a data sample x0:
q(xt | xt-1) = N(xt; √(1-βt)xt-1, βtI)
where βt is a noise schedule that increases over time. This process can be reparameterized as:
xt = √(αt)x0 + √(1-αt)ε
where αt = Π(1-βi) from i=1 to t, and ε ~ N(0, I).
Reverse Process
The goal is to learn the reverse process, which gradually denoises the data:
pθ(xt-1 | xt) = N(xt-1; μθ(xt, t), σt^2I)
where μθ is learned by a neural network.
Training Objective
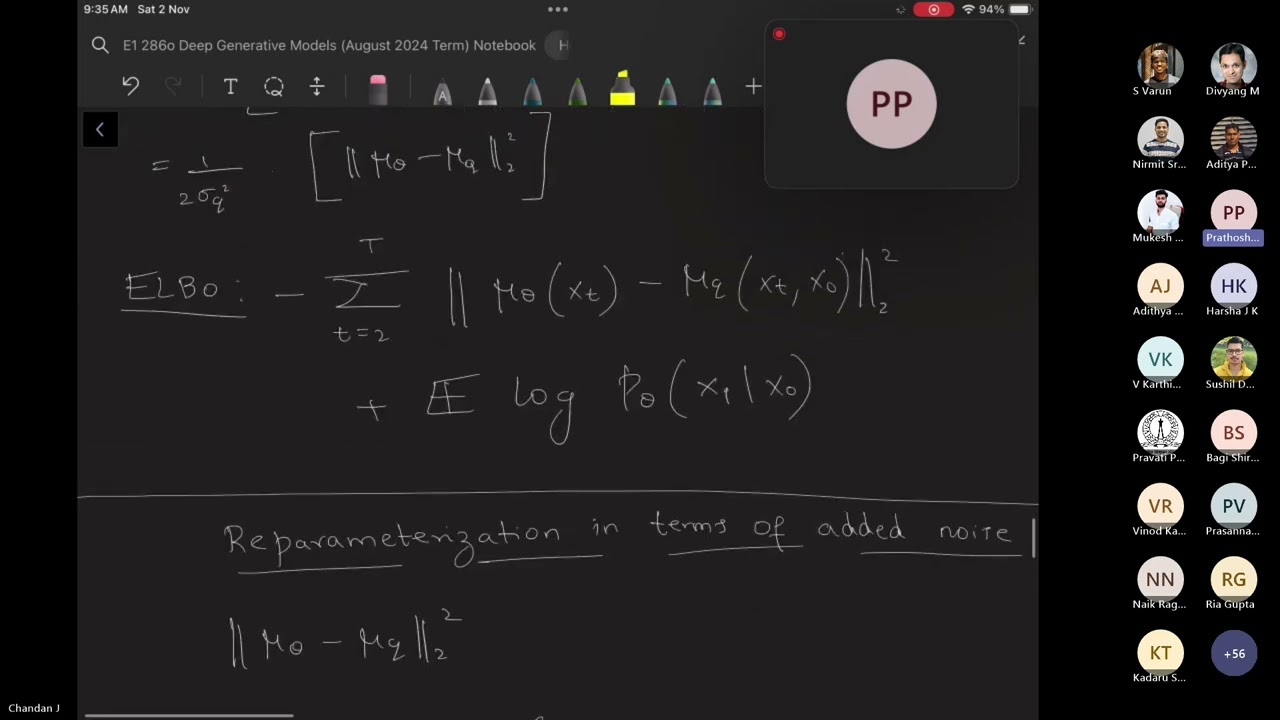
DDPMs are trained to minimize the variational lower bound (ELBO) of the log-likelihood. After some simplifications, the training objective becomes:
L = Et,ε[||ε - εθ(xt, t)||^2]
where εθ is the noise prediction network.
Sampling
To generate new samples, we start from pure noise xT and iteratively apply the learned reverse process:
xt-1 = 1/√(αt) * (xt - (1-αt)/√(1-αt) * εθ(xt, t)) + σt * z
where z ~ N(0, I).
Denoising Diffusion Implicit Models (DDIMs)
DDIMs address two key limitations of DDPMs:
- Slow sampling due to the need for many denoising steps
- Inability to perform posterior inference (inversion)
Non-Markovian Forward Process
DDIMs introduce a family of non-Markovian forward processes that share the same marginal distribution q(xt|x0) as DDPMs:
qσ(x1:T|x0) = q(xT|x0) Π qσ(xt-1|xt,x0)
where qσ(xt-1|xt,x0) is a Gaussian with a carefully chosen mean and variance.
Training
Interestingly, DDIMs can be trained using the exact same procedure as DDPMs. This is because the ELBO only depends on q(xt|x0), which remains unchanged in DDIMs.
Inference
The key difference lies in the inference process. DDIMs use a different reverse process:
pθ(xt-1|xt) = N(xt-1; μ̃θ(xt,t), σ̃t^2I)
where μ̃θ and σ̃t are functions of the DDPM's learned parameters.
Deterministic Encoding
By setting σ=0, we obtain a deterministic forward process. This enables inversion - mapping a data point to its latent representation and back.
Advantages of DDIMs
- Faster Sampling: DDIMs can generate high-quality samples using fewer denoising steps compared to DDPMs.
- Inversion Capability: With deterministic encoding, DDIMs can map data points to latent representations and back.
- Implicit Training: Training a DDPM implicitly trains a family of DDIMs, providing flexibility at inference time.
Applications
Diffusion models, particularly DDIMs, have found success in various applications:
- Image Generation: State-of-the-art results in unconditional and conditional image generation.
- Text-to-Image Synthesis: Models like DALL-E 2 and Stable Diffusion use diffusion models for generating images from text descriptions.
- Image Editing: Inversion capabilities allow for semantic image editing in the latent space.
- Super-Resolution: Generating high-resolution images from low-resolution inputs.
- Inpainting: Filling in missing or corrupted parts of images.
Conditional Generation
Diffusion models can be extended to conditional generation tasks by incorporating class information or other conditioning signals. This is typically done through classifier guidance or classifier-free guidance techniques.
Classifier Guidance
In classifier-guided diffusion, an additional classifier is trained on noisy samples xt. The gradient of the classifier's output with respect to the input is used to guide the denoising process towards generating samples of a specific class.
Classifier-Free Guidance
Classifier-free guidance eliminates the need for an external classifier. Instead, it uses a conditional diffusion model trained on both labeled and unlabeled data, allowing for smoother interpolation between conditional and unconditional generation.
Latent Diffusion Models
To improve computational efficiency, especially for high-resolution images, latent diffusion models apply the diffusion process in a lower-dimensional latent space. This is typically achieved by:
- Training an autoencoder (e.g., VQ-VAE) on the data.
- Applying the diffusion process in the latent space of the autoencoder.
- Using the autoencoder's decoder to map the generated latent samples back to the data space.
This approach is used in models like Stable Diffusion, enabling faster training and inference on high-resolution images.
Conclusion
Diffusion models, particularly DDPMs and DDIMs, have revolutionized generative modeling, achieving remarkable results in image generation and related tasks. Their ability to produce high-quality samples, perform inversion, and handle conditional generation makes them versatile tools for various applications.
As research in this area continues, we can expect further improvements in sampling speed, model efficiency, and the range of tasks that diffusion models can tackle. The success of diffusion models in image generation also opens up possibilities for applying similar principles to other domains, such as audio synthesis and 3D shape generation.
By understanding the core concepts behind DDPMs and DDIMs, researchers and practitioners can better leverage these powerful models and contribute to their ongoing development and application in the field of artificial intelligence and computer vision.
Article created from: https://youtu.be/_QCsp4ZdKLU?feature=shared


