Create articles from any YouTube video or use our API to get YouTube transcriptions
Start for freeIntroduction
Understanding Transformers is crucial for anyone working in natural language processing or machine learning. This guide provides a comprehensive walkthrough of implementing GPT-2 from scratch, offering insights into the inner workings of this powerful language model.
Prerequisites
Before diving into the implementation, it's helpful to have:
- A basic understanding of Python and PyTorch
- Familiarity with neural network concepts
- Some knowledge of natural language processing
Setting Up the Environment
To begin, we'll need to set up our development environment. This typically involves:
- Installing Python
- Setting up a virtual environment
- Installing PyTorch and other necessary libraries
The Transformer Architecture
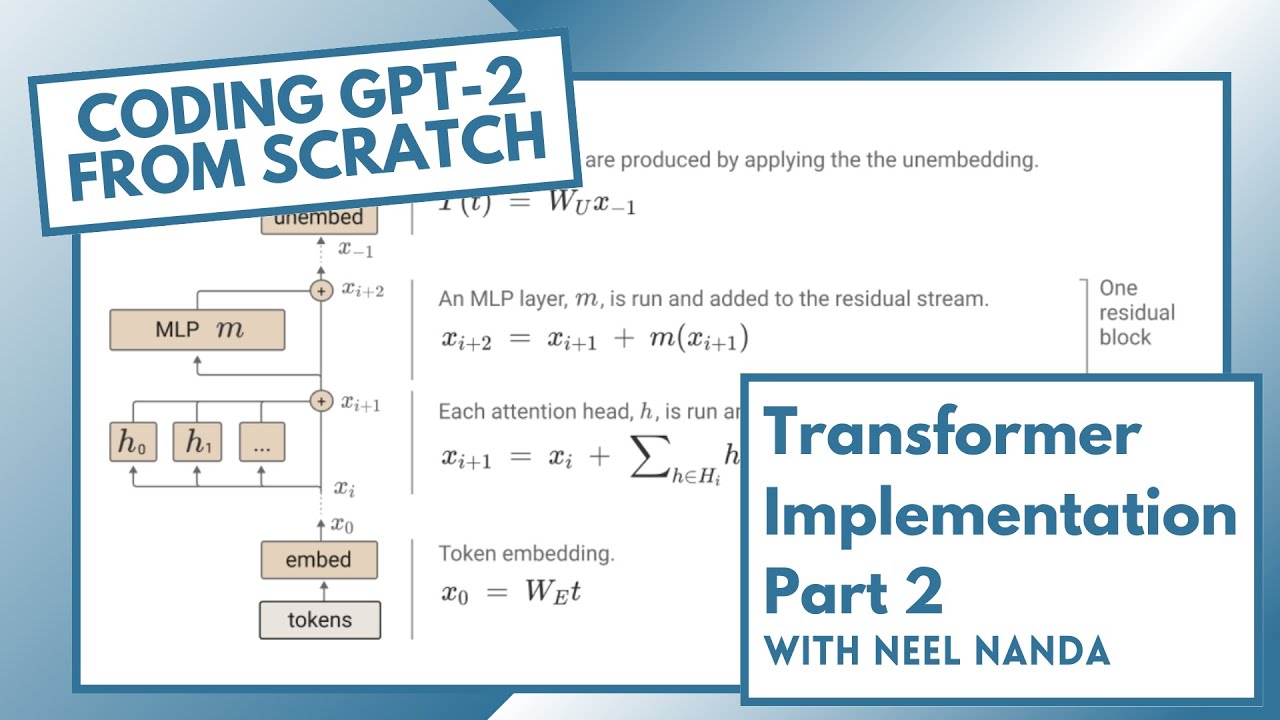
The Transformer architecture is the foundation of GPT-2. Let's break down its key components:
Embedding Layer
The embedding layer converts input tokens into vectors. It consists of:
- Token embeddings
- Positional embeddings
Transformer Blocks
Transformer blocks are the core of the model. Each block contains:
- Multi-head attention layer
- Feed-forward neural network
- Layer normalization
Output Layer
The output layer converts the final hidden states into logits for next token prediction.
Implementing GPT-2 Components
Layer Normalization
Layer normalization is crucial for stabilizing the network. Here's a basic implementation:
class LayerNorm(nn.Module):
def __init__(self, config):
super().__init__()
self.weight = nn.Parameter(torch.ones(config.d_model))
self.bias = nn.Parameter(torch.zeros(config.d_model))
self.eps = config.layer_norm_epsilon
def forward(self, x):
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
return self.weight * (x - mean) / (std + self.eps) + self.bias
Embedding Layer
The embedding layer combines token and positional embeddings:
class Embedding(nn.Module):
def __init__(self, config):
super().__init__()
self.token_embeddings = nn.Embedding(config.vocab_size, config.d_model)
self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.d_model)
def forward(self, input_ids):
seq_length = input_ids.size(1)
position_ids = torch.arange(seq_length, dtype=torch.long, device=input_ids.device)
position_ids = position_ids.unsqueeze(0).expand_as(input_ids)
token_embeddings = self.token_embeddings(input_ids)
position_embeddings = self.position_embeddings(position_ids)
return token_embeddings + position_embeddings
Multi-Head Attention
Multi-head attention is a key component of the Transformer. Here's a simplified implementation:
class MultiHeadAttention(nn.Module):
def __init__(self, config):
super().__init__()
self.num_heads = config.num_heads
self.d_model = config.d_model
self.d_head = self.d_model // self.num_heads
self.query = nn.Linear(self.d_model, self.d_model)
self.key = nn.Linear(self.d_model, self.d_model)
self.value = nn.Linear(self.d_model, self.d_model)
self.out = nn.Linear(self.d_model, self.d_model)
def split_heads(self, x):
batch_size, seq_length, _ = x.size()
return x.view(batch_size, seq_length, self.num_heads, self.d_head).transpose(1, 2)
def forward(self, x, mask=None):
q = self.split_heads(self.query(x))
k = self.split_heads(self.key(x))
v = self.split_heads(self.value(x))
attn_scores = torch.matmul(q, k.transpose(-1, -2)) / math.sqrt(self.d_head)
if mask is not None:
attn_scores = attn_scores.masked_fill(mask == 0, float('-inf'))
attn_probs = F.softmax(attn_scores, dim=-1)
context = torch.matmul(attn_probs, v)
context = context.transpose(1, 2).contiguous().view(batch_size, seq_length, self.d_model)
return self.out(context)
Feed-Forward Network
The feed-forward network processes information at each position:
class FeedForward(nn.Module):
def __init__(self, config):
super().__init__()
self.fc1 = nn.Linear(config.d_model, config.d_ff)
self.fc2 = nn.Linear(config.d_ff, config.d_model)
self.activation = nn.GELU()
def forward(self, x):
return self.fc2(self.activation(self.fc1(x)))
Transformer Block
A Transformer block combines multi-head attention and feed-forward layers:
class TransformerBlock(nn.Module):
def __init__(self, config):
super().__init__()
self.attention = MultiHeadAttention(config)
self.feed_forward = FeedForward(config)
self.layer_norm1 = LayerNorm(config)
self.layer_norm2 = LayerNorm(config)
def forward(self, x, mask=None):
attn_output = self.attention(self.layer_norm1(x), mask)
x = x + attn_output
ff_output = self.feed_forward(self.layer_norm2(x))
return x + ff_output
GPT-2 Model
Now, we can combine all these components to create the full GPT-2 model:
class GPT2(nn.Module):
def __init__(self, config):
super().__init__()
self.embedding = Embedding(config)
self.blocks = nn.ModuleList([TransformerBlock(config) for _ in range(config.num_layers)])
self.layer_norm = LayerNorm(config)
self.lm_head = nn.Linear(config.d_model, config.vocab_size, bias=False)
def forward(self, input_ids, mask=None):
x = self.embedding(input_ids)
for block in self.blocks:
x = block(x, mask)
x = self.layer_norm(x)
return self.lm_head(x)
Training the Model
Training GPT-2 involves several steps:
- Preparing the dataset
- Setting up the optimizer
- Defining the loss function
- Creating the training loop
Here's a basic training loop:
model = GPT2(config).to(device)
optimizer = torch.optim.AdamW(model.parameters(), lr=config.learning_rate)
for epoch in range(config.num_epochs):
for batch in dataloader:
input_ids = batch['input_ids'].to(device)
labels = batch['labels'].to(device)
outputs = model(input_ids)
loss = F.cross_entropy(outputs.view(-1, config.vocab_size), labels.view(-1))
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Epoch: {epoch}, Loss: {loss.item()}")
Generating Text
Once the model is trained, we can use it to generate text:
def generate_text(model, prompt, max_length=100):
model.eval()
input_ids = tokenizer.encode(prompt, return_tensors='pt').to(device)
with torch.no_grad():
for _ in range(max_length):
outputs = model(input_ids)
next_token_logits = outputs[:, -1, :]
next_token = torch.argmax(next_token_logits, dim=-1).unsqueeze(-1)
input_ids = torch.cat([input_ids, next_token], dim=-1)
if next_token.item() == tokenizer.eos_token_id:
break
return tokenizer.decode(input_ids[0])
Conclusion
Implementing GPT-2 from scratch provides valuable insights into the workings of Transformer-based language models. This guide covered the key components and steps involved in building and training a GPT-2 model. By understanding these fundamentals, you'll be better equipped to work with and modify more complex language models in the future.
Remember that this implementation is a simplified version of GPT-2. The full model includes additional optimizations and features that improve performance and generation quality. As you continue to explore language models, you'll encounter more advanced techniques and architectures that build upon these core concepts.
Experimenting with different hyperparameters, model sizes, and training data can lead to interesting variations in model performance and generated text. Don't be afraid to modify the code and try new ideas – that's how progress in machine learning is made!
Finally, it's worth noting that while understanding the internals of models like GPT-2 is valuable, many practical applications today use pre-trained models and fine-tuning techniques. Libraries like Hugging Face's Transformers make it easy to work with state-of-the-art language models without having to implement everything from scratch.
Happy coding, and enjoy your journey into the fascinating world of language models!
Article created from: https://youtu.be/dsjUDacBw8o?feature=shared


